NVIDIA GB200 Interconnect Architecture Analysis-NVLink, InfiniBand, and Future Trends
1. NVLink Bandwidth Calculation
There is a lot of confusion in NVIDIA’s calculation of NVLink transmission bandwidth and the concept of SubLink/Port/Lane. Typically, the NVLink 5 bandwidth of a single GB200 is 1.8TB/s, which is calculated by bandwidth-oriented individuals in bytes per second (Byte/s). However, on NVLink Switches or IB/Ethernet switches and network cards, Mellanox’s perspective calculates it in terms of network bandwidth, usually in bits per second (bit/s), based on the transmitted data bits.
Here, we’ll explain in detail the calculation method of NVLink. Starting from NVLink 3.0, it is composed of four differential pairs to form a “sub-link” (often referred to by NVIDIA as Port/Link, with some ambiguity in definition). These 4 pairs of differential signal lines simultaneously contain both the receiving and transmitting directions of signal lines. Typically, when calculating network bandwidth, a 400Gbps interface refers to the ability to transmit and receive data at 400Gbps simultaneously, as shown in the diagram below:

It consists of a total of 4 pairs of differential signal lines, each having RX/TX pairs. From the network’s perspective, it is a unidirectional 400Gbps link, while from the memory bandwidth perspective, it supports a memory bandwidth of 100GB/s.
1.1 NVLINK 5.0 Interconnect Bandwidth
In the Blackwell generation, 224G Serdes are utilized, meaning the transmission rate of each sub-link is 200Gbps * 4 (4 pairs of differential lines) / 8 = 100GB/s. From a network perspective, the unidirectional bandwidth is 400Gbps. A B200 comprises a total of 18 sub-links, resulting in a bandwidth of 100GB/s * 18 = 1.8TB/s. From the network perspective, this is equivalent to nine unidirectional 400Gbps interfaces. Similarly, in the introduction of NVSwitch, it is stated that Dual 200Gb/sec SerDes form a 400Gbps Port.

To facilitate the discussion in the following sections, we provide the following unified definitions for these terms:

The NVLINK bandwidth of the B200 is 1.8TB/s, consisting of 18 Ports, each with a bandwidth of 100GB/s. Each Port comprises four pairs of differential lines and includes two sets of 224Gbps Serdes (2x224G PAM4, calculated as a unidirectional 400Gbps bandwidth per Port from a network interface perspective).
1.2 NVLINK 4.0 Interconnect Bandwidth
Let’s further elaborate on Hopper. In NVLINK 4.0, 112G Serdes are utilized, meaning a single pair of differential signal lines can transmit 100Gbps. Therefore, each sub-link of NVLINK 4.0 comprises 4x100Gbps = 50GB/s. In the Hopper generation products that support NVLINK 4.0, there are 18 sub-links (ports) per H100, resulting in a total bandwidth of 50GB/s * 18 = 900GB/s. When utilizing eight cards in a single machine, they are interconnected using four NVSwitches, as shown in the diagram below:

Additionally, it can further expand to form a cluster of 256 cards by adding a second-level switch.

Expansion interfaces employ OSFP optical modules.
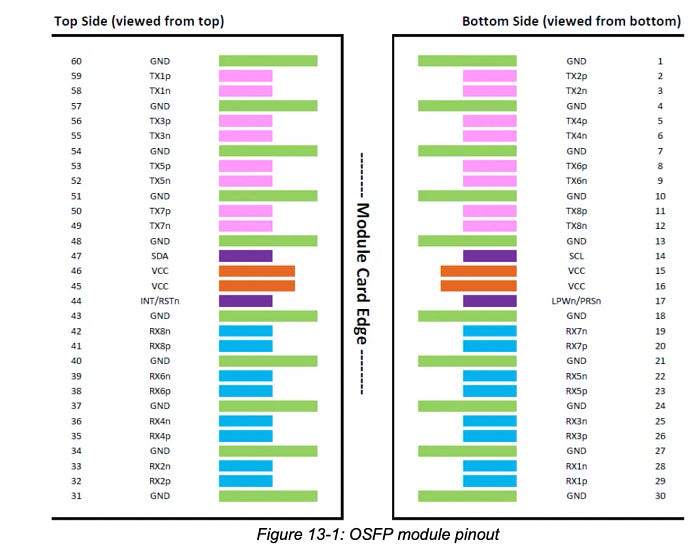
As depicted in the following diagram, an OSFP optical module can support 16 pairs of differential signal lines, thus enabling each OSFP to support 4 NVLINK Ports.
In other words, the NVLink Switch shown below includes 32 OSFP optical module interfaces, enabling a cumulative support for 32 * 4 = 128 NVLINK4 Ports.

2. GB200 NVL72
The specifications of GB200 NVL72 are depicted in the following diagram. This article primarily discusses issues related to NVLINK.
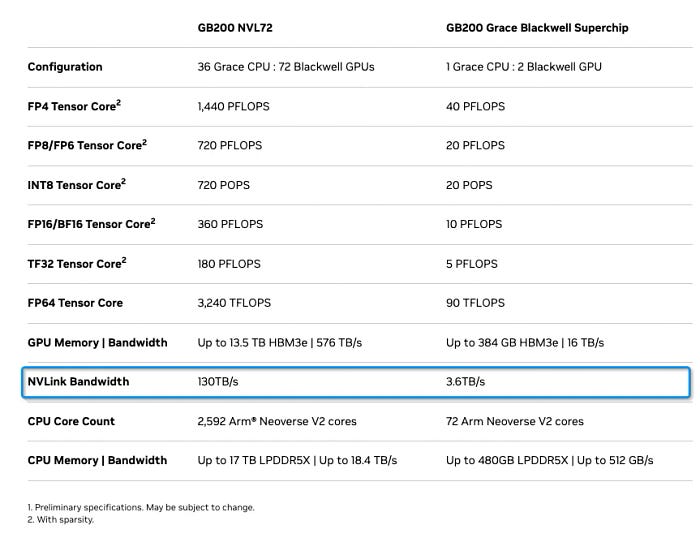
A GB200 comprises one Grace CPU with 72 cores and two Blackwell GPUs.

The entire system consists of Compute Trays and Switch Trays. A Compute Tray contains two GB200 subsystems, totaling four Blackwell GPUs.

A Switch Tray contains two NVLINK Switch chips, providing a cumulative total of 72 * 2 = 144 NVLINK Ports. The structure of a single chip is as follows, with 36 ports each on the top and bottom, providing a bandwidth of 7.2TB/s. According to the networking algorithm, it has a switching capacity of 28.8Tbps, slightly smaller than the leading 51.2Tbps switching chips available today. However, it’s essential to note that this reduction is due to the implementation of features such as SHARP (NVLS).

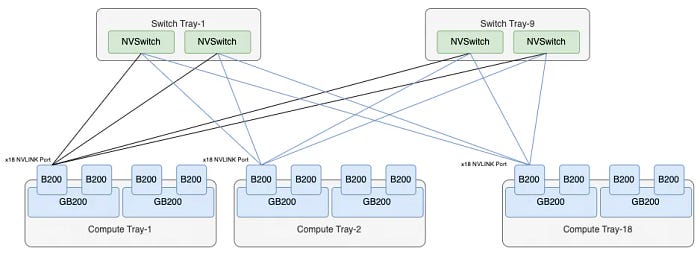
The entire cabinet supports 18 Compute Trays and 9 Switch Trays, thus forming a single-cabinet architecture with 72 Blackwell chips fully interconnected, known as NVL72.

A single GB200 subsystem contains 2 * 18 = 36 NVLink5 Ports. The external interconnection of the entire system does not adopt OSFP optical module interfaces but directly connects through a rear copper backplane, as shown below:


The assertions made by financial analysts regarding the transition from optical to copper are somewhat one-sided. The design consideration for the Hopper generation was a relatively loosely coupled connection, leading these analysts to overemphasize the demand for optical modules. Moreover, there were more flexible requirements for cabinet heat dissipation deployment at that time. However, this generation involves the delivery of entire cabinets within a single cabinet, akin to the delivery logic of IBM mainframes, naturally leading to the selection of a copper backplane. Additionally, individual B200s have higher power consumption, and liquid cooling delivery also imposes power constraints. From a power consumption perspective, switching to copper can significantly reduce power consumption. However, this does not imply that copper interconnection will persist in the future, as detailed analysis will be provided in subsequent sections.
The interconnect topology of the entire NVL72 is as follows:
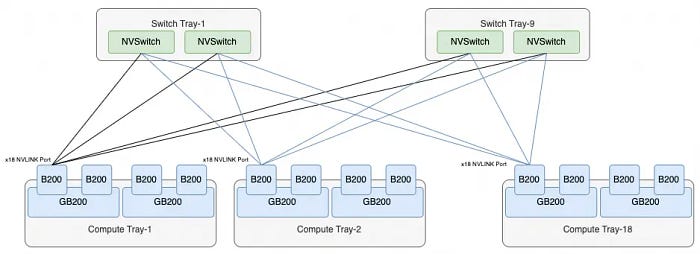
Each B200 has 18 NVLINK Ports, and with 9 Switch Trays, totaling 18 NVLINK Switch chips, each B200 port is connected to an NVSwitch chip. Consequently, the entire system comprises precisely 72 ports per NVSwitch, forming the NVL72 architecture, connecting all 72 B200 chips.
3. NVL576
We notice that within the NVL72 cabinet, all switches no longer have additional interfaces for interconnecting to form larger-scale two-layer switch clusters. From NVIDIA’s official images, we can see that 16 cabinets form two rows. Although a total of 72 * 8 cabinets constitute a 576-card cluster in a liquid-cooled solution, from the cabinet connection perspective, these cards are mostly interconnected via Scale-Out RDMA networks rather than through Scale-Up NVLINK networks.

For a cluster of 32,000 cards, the same NVL72 cabinets are used. One column comprises 9 cabinets, with 4 NVL72 cabinets and 5 network cabinets, forming a Sub-Pod and interconnected via an RDMA Scale-Out network.

However, this is not the so-called NVL576. To support NVL576, 18 NVSwitches are required for every 72 GB200s, making it impractical to fit into a single cabinet. In fact, we notice the following statement from the official documentation:

The official documentation states that NVL72 has both a single-cabinet version and a double-cabinet version. In the double-cabinet version, each Compute Tray only contains one GB200 subsystem. On the other hand, we notice that there are spare copper cable connectors on the NVSwitch, which are likely custom-made for different copper backplane connections.

It’s unclear whether these interfaces will have some OSFP Cages reserved for the second layer of NVSwitch interconnection on the copper backplane. However, this approach has an advantage: the single-cabinet version is Non-Scalable, while the double-cabinet version is Scalable, as shown below:
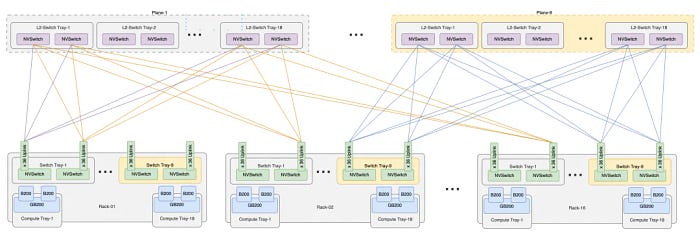
The double-cabinet version has 18 NVSwitch Trays, which can be back-to-back interconnected to form NVL72. Although there are twice as many switches, each switch provides 36 external interconnects for uplinking for future expansion to a 576-card cluster. With 16 cabinets required for NVL576, the cumulative number of uplink ports is 648 * 16 = 10,368. In practice, this can be achieved by 9 second-layer switch planes, each with 36 sub-planes, constituted by 18 Switch Trays. The interconnection structure of NVL576 is illustrated below:
4. NVLINK and InfiniBand
When discussing the relationship between NVLINK and GB200, it is inevitable to involve InfiniBand technology. NVLINK is a proprietary interconnect technology developed by NVIDIA for its GPU accelerators, while GB200 is a GPU chip built based on NVLINK. At the same time, InfiniBand, as a widely used general-purpose interconnect technology in data centers and high-performance computing systems, also plays an important role in this field.
Although NVLINK plays a crucial role in building GPU clusters and related high-performance computing systems, it is not the only interconnect option. In large-scale data centers and supercomputing systems, efficient communication with various devices and server nodes is typically required, and InfiniBand, as a universal and standardized interconnect technology, provides the capability to communicate effectively with different devices and nodes.
In fact, many data centers and supercomputing systems adopt a hybrid interconnect architecture, utilizing both NVLINK and InfiniBand technologies. In this hybrid architecture, NVLINK is often used to connect GPU nodes for accelerating compute and deep learning tasks, while InfiniBand is used to connect general-purpose server nodes, storage devices, and other data center equipment to achieve coordination and efficient operation of the entire system.

By combining NVLINK and InfiniBand technologies, data centers and supercomputing systems can fully leverage various devices and resources to achieve higher performance and efficiency. Additionally, this hybrid architecture offers more flexible deployment and expansion options to meet the requirements of different application scenarios.
In the future, as data centers and supercomputing systems continue to evolve and advance, we can expect NVLINK and InfiniBand technologies to continue playing important roles and continually improving performance and functionality to meet the growing demands of data processing. In this process, high-speed interconnect devices such as optical modules will continue to play a crucial role in providing higher bandwidth and lower latency solutions for system interconnectivity.

NADDOD’s expertise in tailored networking solutions ensures that organizations can optimize their interconnect architectures to meet specific workload requirements and operational needs. Whether it’s deploying high-speed InfiniBand fabrics, optimizing network topologies, or implementing customized interconnect solutions, NADDOD’s commitment to excellence empowers businesses to unleash the full potential of their data center ecosystems.
